










Pythonでブログの検索順位を取得するツールを作っています。
前回までに、
- キーワードでGoogle検索
- 検索結果からブログ順位を取得
- 検索キーワード一覧をExcelファイルから取得
する部分を作ってきました。

今回は、今までの機能を実行後にExcelに結果を書き出す部分を作ってみます。
ちなみに、この記事のタイトルをPython超初心者から、ただの初心者に変更してみました。
さすがに「超」初心者は脱したでしょう。
キーワード検索してExcelファイルに書き出す
キーワードでGoogle検索して、ブログの順位をExcelファイルに書き出してみます。
ソースコード
作成したソースコードです。
全部載せます。
前回までのコードと被る部分がほとんどですが、今回追加した箇所のみ抜き出したら流れが分かり辛いので。
やっていることは、
- 検索キーワード一覧をExcelから読み込む
- キーワードでGoogle検索する
- 検索順位をExcelに書き出す
です。2~3を検索キーワード分繰り返します。
import requests as web
import bs4
import openpyxl as px
import datetime
#Excelブックオープン
book = px.load_workbook('ブログ検索順位.xlsx')
#シート名取得
#sheet = book.get_sheet_names()
sheet = book.sheetnames
#シート名表示
print(sheet)
for i in range(len(sheet)): #シート数分ループ
if sheet[i] == '検索ワード':
word_sheet = sheet[i]
#シートを設定
#ws = book.get_sheet_by_name(word_sheet)
ws = book[word_sheet]
if sheet[i] == '検索順位':
#シートを設定
wr = book[sheet[i]]
#最大行の取得
erow = ws.max_row
word_list = [] #検索ワードリスト
for i in range(erow): #最終行までループ
#セルの値をリストに追加
word_list.append(ws.cell(row=i+1,column=1).value)
#検索ワードリストの表示
print(word_list)
#検索順位を書き出す列
ecol = wr.max_column
now_col = ecol+1
td = datetime.date.today() #今日の日付
wr.cell(row=1,column=now_col,value=td)
for ilist in range(len(word_list)):
print('------------------------------------------------')
#検索キーワード
keyword = word_list[ilist]
print('検索ワード:' + keyword)
#出力シートにキーワードを書く(既にある場合はスルー)
flg = 0
erow = wr.max_row #最終行
for i in range(erow):
if wr.cell(row=i+1,column=1).value == keyword:
flg = 1
now_row = i+1
break
if flg != 1:
wr.cell(row=erow+1,column=1,value=keyword)
now_row = erow+1
#リクエストヘッダー
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
#上位50件まで検索結果を取得
url = 'https://www.google.co.jp/search?hl=ja&num=50&q=' + keyword
#接続
response = web.get(url, headers=headers)
with open('test.html','w',encoding='utf-8') as f:
f.write(response.text)
#HTTPステータスコードをチェック(200以外は例外処理)
response.raise_for_status()
#取得したHTMLをパース
soup = bs4.BeautifulSoup(response.content, 'html.parser')
#検索結果のタイトルとリンクを取得
ret_link = soup.select('.r > a')
title_list = []
url_list = []
for i in range(len(ret_link)):
# タイトルのテキスト部分を取得
title_txt = ret_link[i].get_text()
# リンクのみを取得し、余計な部分を削除する
url_link = ret_link[i].get('href').replace('/url?q=','')
title_list.append(title_txt)
url_list.append(url_link)
blog_url = "https://rikei-fufu.com"
flg = 0
for i in range(len(title_list)):
str_url = url_list[i]
if str_url.startswith(blog_url):
print('ブログが検索結果にありました')
blog_no = i + 1
blog_title = title_list[i]
print('順位:' + str(blog_no) + '位')
print('記事:' + blog_title)
flg = 1
#出力シート
wr.cell(row=now_row,column=2,value=str_url)
wr.cell(row=now_row,column=3,value=blog_title)
wr.cell(row=now_row,column=now_col,value=blog_no)
break
if flg != 1:
print('検索範囲内にブログはありませんでした。')
book.save('ブログ検索順位.xlsx') 追加箇所
今回新たに追加した機能を紹介します。
forループで複数の検索キーワードで検索する
検索キーワードは複数あるので、「Google検索して順位を取得する」という動作をforループで回します。
該当箇所はここ
for ilist in range(len(word_list)):
keyword = word_list[ilist](今回はforループがたくさんあるので、ループ変数を「ilist」にして混乱しないようにしました。)
日付を取得
Excelファイルに検索順位を書き出す際、日付も一緒に出力していきたいので、日付を取得してみます。
「datetime」モジュールをインポートします。(pipでインストールする必要はなかったです。標準で入っています。)
import datetime
td = datetime.date.today() #今日の日付
Excelファイルに検索結果を書き出す
ここが今回の肝。
シート変数「wr」に検索結果を出力するシートを設定し、cellに行番号、列番号と書き出す値を入れます。
セルに入れる値も引数に書くのがポイント。
wr.cell(row=now_row,column=2,value=str_url)
wr.cell(row=now_row,column=3,value=blog_title)
wr.cell(row=now_row,column=now_col,value=blog_no)VBAの方が書き出し方が簡単で分かり易いな・・・と。
いちいち「row=***,columns=***」と書かなきゃいけないのが面倒くさいですね。
引数に順番に値のみ書くようにすればいいのにな。
また、Excelファイルの保存は
book.save('ブログ検索順位.xlsx') でできます。
ファイル名を読み込み時から変えれば新規に保存されますが、同じなら上書き保存です。
ファイル書き出し結果
上記のソースコードを実行して出力された結果は

まぁ、やりたいことはできていますね。
順位もしっかり表示できていますし。
しかし、記事タイトルに書かれた文字列が、「Baby Kumon(ベビーくもん)に2年間(24回)通った効果 | 理系夫婦の方程式https://rikei-fufu.com/2019/04/12/post-424/」というふうに、タイトルの後にURLも付いてしまっています。
また、日付も「2019-06-27」というフォーマットが気持ち悪い。
好みの見た目になるように、少し改善してみます。
見た目を改善しよう
出力結果の見た目が良くなるように改善したソースコードです。
import requests as web
import bs4
import openpyxl as px
import datetime
#Excelブックオープン
book = px.load_workbook('ブログ検索順位.xlsx')
#シート名取得
#sheet = book.get_sheet_names()
sheet = book.sheetnames
#シート名表示
print(sheet)
for i in range(len(sheet)): #シート数分ループ
if sheet[i] == '検索ワード':
word_sheet = sheet[i]
#シートを設定
#ws = book.get_sheet_by_name(word_sheet)
ws = book[word_sheet]
if sheet[i] == '検索順位':
#シートを設定
wr = book[sheet[i]]
#最大行の取得
erow = ws.max_row
word_list = [] #検索ワードリスト
for i in range(erow): #最終行までループ
#セルの値をリストに追加
word_list.append(ws.cell(row=i+1,column=1).value)
#検索ワードリストの表示
print(word_list)
#検索順位を書き出す列
i=1
while wr.cell(row=1,column=i).value != None:
i=i+1
now_col = i
td = datetime.date.today().strftime('%Y/%m/%d') #今日の日付
wr.cell(row=1,column=now_col,value=td)
for ilist in range(len(word_list)):
print('------------------------------------------------')
#検索キーワード
keyword = word_list[ilist]
print('検索ワード:' + keyword)
#出力シートにキーワードを書く(既にある場合はスルー)
flg = 0
i=0
while wr.cell(row=i+1,column=1).value != None: #空白セルまでループ
if wr.cell(row=i+1,column=1).value == keyword:
flg = 1
now_row = i+1
break
i=i+1
if flg != 1:
wr.cell(row=i+1,column=1,value=keyword)
now_row = i+1
print('行:' + str(now_row))
#リクエストヘッダー
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
#上位50件まで検索結果を取得
url = 'https://www.google.co.jp/search?hl=ja&num=50&q=' + keyword
#接続
response = web.get(url, headers=headers)
#HTTPステータスコードをチェック(200以外は例外処理)
response.raise_for_status()
#取得したHTMLをパース
soup = bs4.BeautifulSoup(response.content, 'html.parser')
#検索結果のタイトルとリンクを取得
ret_link = soup.select('.r > a')
title_list = []
url_list = []
for i in range(len(ret_link)):
# タイトルのテキスト部分を取得
title_txt = ret_link[i].get_text()
# リンクのみを取得し、余計な部分を削除する
url_link = ret_link[i].get('href').replace('/url?q=','')
title_list.append(title_txt)
url_list.append(url_link)
blog_url = "https://rikei-fufu.com"
flg = 0
for i in range(len(title_list)):
str_url = url_list[i]
if str_url.startswith(blog_url):
print('ブログが検索結果にありました')
blog_no = i + 1
blog_title_s = title_list[i]
#タイトルの後のURLは削除
cut=blog_title_s.find(blog_url) #インデックス
blog_title = blog_title_s[:cut]
print('順位:' + str(blog_no) + '位')
print('記事:' + blog_title)
flg = 1
#出力シート
wr.cell(row=now_row,column=2,value=str_url)
wr.cell(row=now_row,column=3,value=blog_title)
wr.cell(row=now_row,column=now_col,value=blog_no)
break
if flg != 1:
print('検索範囲内にブログはありませんでした。')
wr.cell(row=now_row,column=now_col,value='×')
book.save('ブログ検索順位.xlsx') 改善点
上記コードのどこが改善点なのかをまとめます。
日付のフォーマットを指定
デフォルトだと「yyyy-mm-dd」形式で出力されてしまうので、「yyyy/mm/dd」とスラッシュで区切るようなフォーマットを指定してみます。
datetime.date.today().strftime('%Y/%m/%d')これでフォーマット指定できます。
記事タイトルからURLを削除
検索結果から取得した記事タイトルにURLが混じっているので、URLを削除します。
この部分を追加しました。
cut=blog_title_s.find(blog_url) #インデックス
blog_title = blog_title_s[:cut]「blog_title_s」は検索結果の記事タイトル文字列、「blog_url」はブログのTOPページURLです。
「find」で文字列の中からブログURLが始まる場所を探します。
「blog_title_s[:cut]」で、ブログURLより前の部分までを取り出して、違う文字列変数に格納しています。
これを「スライシング」というようです。
参考: Pythonの文字列を抽出する方法まとめ
これで文字列から不要な部分を削除できます。
最終行・最終列の取得方法の変更
プログラムを何回も実行していると、Excelの最終行・最終列の取得結果がおかしくなり、うまくファイルに書き出せないときがありました。
セルの値を消していても、「空白ではないセル」として判断されちゃっているよう。
なので、「max_row」といった関数は使わず、while文で空白セルまでループして最終行を求めるようにしました。
最終列の取得
i=1
while wr.cell(row=1,column=i).value != None:
i=i+1最終行の取得
i=0
while wr.cell(row=i+1,column=1).value != None: #空白セルまでループ
i=i+1cell(row,column)==None
が空白セルとなります。
このやり方だと上手く最終行・最終列の取得ができるようになります。
ファイル書き出し結果
改善してみたコードを実行してみると
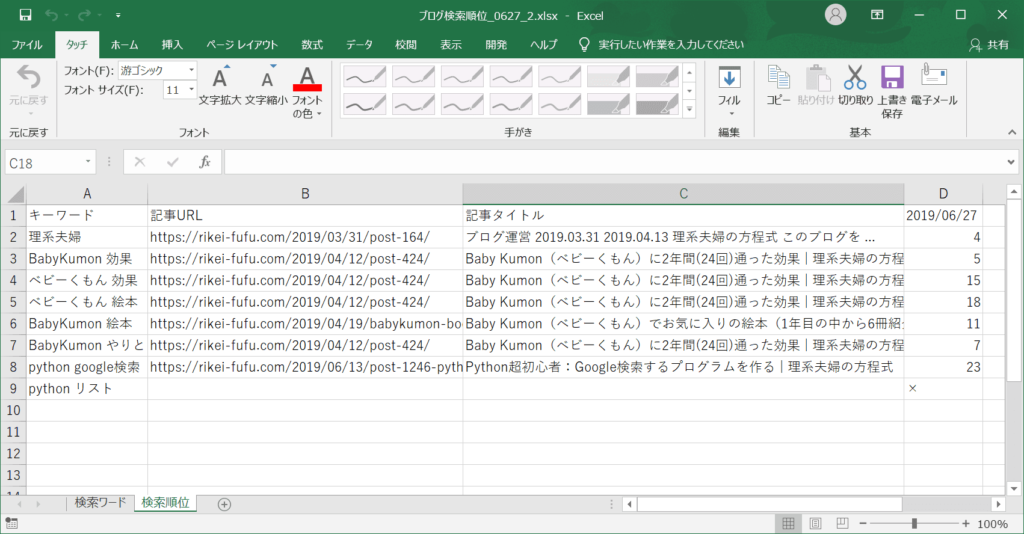
このようなExcelファイルができました。
うん、良くなりました。
日付も「yyyy/mm/dd」形式ですし、記事タイトルもURLが消えました。
(「|理系夫婦の方程式」の部分も消した方がスッキリするな・・・後でやろう)
あえて検索50位以内に入らなそうなキーワードも追加してみましたが、きちんと「×」が出力できています。(D9セル)
基本的な機能はこれで備わったかな。
あとは、やはりデスクトップアプリとして使えるようにGUIで操作できるようにしたいのと、グラフも作れるようにしたい。
理想の検索順位取得ツールとなるように、これからもチャレンジしていきます。
んじゃ、また~
おススメのプログラミング独学方法はこちらの記事にまとめました!







コメント