










私は元々はfortranを第一言語として、長年使ってきたが、現在の仕事では基本的にpythonを使って計算コードを書いています。
pythonは便利なモジュールがたくさん用意されており、計算原理を理解せずとも簡単に色々できます。
例えば顔認識、機械学習などの高度な数学知識が必要な計算でも10分程度でコードが組めました。
しかし、pythonの計算速度は速くないようです。
最近も仕事で重い計算をしないといけなくなったが、pythonで組んだら超絶時間がかかって、高速化しないといけなくなって、重い計算部分のみをfortranに書き換えました。
今回はそこで使用した、pythonからfortranを呼び出す方法を記しておきます。
ネット上はいろいろと手法はあるが、かなり複雑だったり、fortranへは入力変数しかなかったり、逆に出力変数しかなかったりするので、今回は最も簡単な方法でかつ、入力・出力変数がある場合を紹介する。3分でできます!
概要: “f2py”を使って、fortranをpythonのモジュールにする
概要図を下記に示しました。
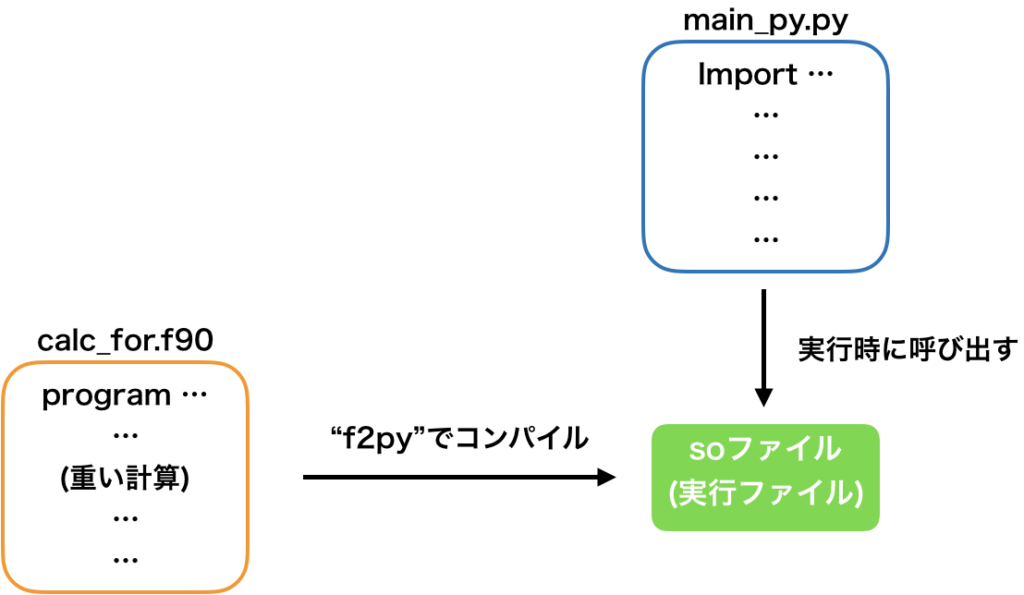
calc_for.f90に計算(例えばとても重い計算)を書き、これを”f2py”でコンパイルします。
こうすると、pythonから呼び出せるsoファイルができ、あとはpythonから呼び出せば良いのです。
f2pyはnumpyのインストールがされていれば、同時にインストールされているようです。もし無ければpipなどを使ってnumpyをインストールしてみてください。
例1: fortranへの入力変数と、fortranからの出力変数があるケース
単にa+bを計算して、その結果としてcを出力するfortranコードを作ってみました。このfortran計算部分をpythonコードから呼び出しています。
まずはfortranコードについて。
! calc_for.f90
subroutine calc_sub(a, b, c) !サブルーチンとして関数を定義して、入力変数・出力変数を共に記す。
integer a, b, c !各変数を定義
intent(in) a,b !「aとbは入力変数だよ」という文
intent(out) c !「cは出力変数だよ」という文
print *, "Calclation in fortran" !単なるターミナル表示
c = a + b !実際の計算
end subroutine calc_sub !サブルーチンを閉じる。
これを次のようなコマンドでコンパイルします。
f2py -m calc_for -c calc_for.f90
これによって、「calc_for.f90」がコンパイルされて、「calc_for」という名前のpythonモジュールとして呼び出せるようになります。
実体としては「calc_for.cpython-38-darwin.so」が作成されています。これがsoファイルという実行ファイルです。このファイル名はシステムによって違ってきますが気にしなくて良いようです。
このファイル「calc_for.f90」はmain関数を含まないので、普通にgfortranでのコンパイルではエラーが出るかも。
また”f2py”では自動的に使用可能なコンパイラーが選択されます。ということは、コンピュータ内にgfortranなどのfortran用コンパイラーが一つもない時には次のようなエラーが出されます。
Could not locate executable gfortran
Could not locate executable f95
…
この場合には、別途fortran用コンパイラーをインストールする必要があります。
一方で、メインのpythonは次のように書きます。
# main_py.py
import calc_for # fortranで作成したファイルをモジュールとして呼び出せるようにする。
# fortranコードへの入力変数を定義する。
a=1
b=2
c = calc_for.calc_sub(a,b) # 実際にfortranコードを呼び出して計算を実行する。
print(c) # 結果を画面出力する。 -> 「3」が得られる。これを実行すれば、fortranでの計算の結果「3」が画面に出力されます。
fortranを呼び出す行では、「calc_for」というファイル(モジュール)内の「calc_sub」というサブルーチンが呼び出す、という意味です。もちろん変数を入力する順番は気にする必要があります。
ちなみに単に「c = calc_for(a,b)」としてしまった場合には、次のようなエラーが出ます。
TypeError: ‘module’ object is not callable
モジュールをそのまま呼ぶなよ、っていう意味。
下記ではもう少し違う例を示したいと思います。
例2: 1次元配列の入出力
1次元配列を2つ入力して、その成分の和を1つの1次元配列として返す例です。
fortranコードが下記。
! calc_for.f90
subroutine calc_sub_2(a, b, c) !サブルーチンの名前をcalc_sub_2に変えました。
integer a(3), b(3), c(3) !入力、出力ともに要素数3の配列を定義
integer i
intent(in) a,b !「aとbは入力変数だよ」という文
intent(out) c !「cは出力変数だよ」という文
print *, "Calclation in fortran"
!実際の計算
do i = 1, 3
c(i) = a(i) + b(i)
end do
end subroutine calc_sub_2注意点としては、あらかじめ入力、出力される変数の次元数、要素数を記述しておく必要があります。
つまり、allocateableとして定義するとうまくいかないので、注意。
コンパイルのための命令文は上と同じです。
f2py -m calc_for -c calc_for.f90
fortranファイルの名前が同じなので、命令文が同じなのも当たり前ですね。1つのファイルにsubroutineはいくらでもかけるので、先のsubroutineの下に付きたしても問題ないです。
次にpythonコード。
# main_py.py
import calc_for # fortranで作成したファイルをモジュールとして呼び出せるようにする。
###########################
# 例1
# fortranへ入力する変数をリストとして定義
a=[1,2,3]
b=[4,5,6]
c = calc_for.calc_sub_2(a,b) # fortranコードを呼び出して計算
print(c) # 結果を画面出力する。 -> [5,7,9]を得る。
###########################
# 例2
# 入力変数をnumpy配列として定義することも可能。
a_np = np.array([1,2,3])
b_np = np.array([4,5,6])
c_np = calc_for.calc_sub_2(a_np,b_np) # fortranコードを呼び出して計算
print(c_np) # 結果を画面出力する。 -> [5,7,9]を得る。これで難なく配列を入力して、その計算結果として配列を受け取ることができました。
例3: 多次元配列の入出力
次に、多次元配列の例を示したいと思います。
2次元配列ができれば、n次元配列も同様にできるだろうから、2次元配列の場合を示します。
今回もfortan内のsubroutineの名前は変えておきました。
! calc_for.f90
subroutine calc_sub_3(a, b, c)
integer a(2,2), b(2,2), c(2,2) !入力変数も出力変数もちゃんと次元数・要素数を指定して宣言
integer i, j
intent(in) a,b !入力変数
intent(out) c !出力変数
print *, "Calclation in fortran"
do i = 1, 2
do j = 1, 2
c(i,j) = a(i,j) + b(i,j) !各々の要素を足し合わせるような計算
end do
end do
end subroutine calc_sub_3コンパイルは先と同様に下記ように行います。
f2py -m calc_for -c calc_for.f90
次にpythonファイルは次のように書きます。
# main_py.py
import calc_for # fortranで作成したファイルをモジュールとして呼び出せるようにする。
#入力変数を定義する。
a=[[1,2],[3,4]]
b=[[5,6],[7,8]]
c = calc_for.calc_sub_3(a,b) #fortranコードに入力変数を投げ、出力変数を受け取る。
print(c) # 結果を画面出力する。 -> [[ 6 8] [10 12]] fortranを呼び出す部分は、ファイル名「calc_for」のsubroutine「calc_sub_3」を呼び出すということを表していて、もちろん変数を入力する順番は気にしないといけないです。
計算速度比較: フィボナッチ数計算を題材に
最後にpythonと、fortran(+python)の計算速度の比較をしてみます。
計算の題材は、フィボナッチ数の計算で、このような計算速度比較ではよく使われる題材のようです。
フィボナッチ数(Fibonacci number)とは次のような数字です。
$$ F_0 = 0 \\ F_1 = 1 \\ F_2 = F_1+F_0 = 1 \\ F_3 = F_2 + F_1 = 2 \\ F_4 = F_3 + F_2 = 3 \\ F_5 = F_4 + F_3 = 5 \\ F_n=F_{n-1}+F_{n-2} $$
Pythonのみの場合
まずはpythonのみで、計算してみました。コードは下記です。F_40を100000回計算させています。
計算時間も測定させます。
#fibo_calc.py
#フィボナッチ数計算(python)
import time
start_time=time.time() #計算開始時刻
input_n = 40
loop_n = 100000
for j in range(loop_n):
F_old_old = 0
F_old = 1
for i in range(input_n):
output_F = F_old_old + F_old
F_old_old = F_old
F_old = output_F
print(output_F)
end_time=time.time() #計算終了時刻
print(end_time-start_time) #計算に要した時間[s]Fortran (+python)の場合
次にメインの重い計算をfortranにさせた場合のコード。
!calc_fibo.f90
subroutine fibo(input_n, loop_n, output_F)
integer*8 input_n, loop_n
integer*8 output_F
integer*8 i, j, F_old, F_old_old
intent(in) input_n, loop_n
intent(out) output_F
do j = 1, loop_n
F_old_old = 0
F_old = 1
do i = 1, input_n
output_F = F_old_old + F_old
F_old_old = F_old
F_old = output_F
end do
end do
end subroutine fiboコンパイルコマンドは下記。
f2py -m calc_fibo -c calc_fibo.f90
ファイル名を変えたので、先とは少しだけ違います。
一方で呼び出すpythonファイルは次のようにしました。
#main_fibo.py
#フィボナッチ数計算(fortran+python)
import time
import calc_fibo
start_time=time.time() #計算開始時刻
input_n = 40
loop_n = 100000
output_F = calc_fibo.fibo(input_n, loop_n)
print(output_F)
end_time=time.time() #計算終了時刻
print(end_time-start_time) #計算に要した時間[s]実行結果の比較
計算自体の結果はもちろん同じ「165580141」という数字が出力されます。これが40番目のフィボナッチ数の値です。
一方で計算時間は下記のように大きな差がでました。
| 計算時間[s] | |
| pythonのみ | 0.52399 |
| fortran (+python) | 0.00119 |
なんと、fortranの方が、pythonよりも500倍も早い速度で計算できたことになります。
もちろんpythonコードの方はもっと「pythonらしい書き方」をすればもっと早く計算できるだろうが、それでもfortranの方がはるかに速いことに間違いはないです。
いくつかの言語の計算速度比較を行ったページを貼っておきます。

pythonからfortranを呼び出すときにも余分に時間が必要なので、pythonの一部のみをfortranに任せる時には、ある程度重い計算を、ゴソっと任せないと意味はないので注意が必要だが、pythonを高速化したい時にfortranを使用するのは1つの手でしょう。
皆さんも時には古典言語と現代言語を混ぜてみては?











コメント